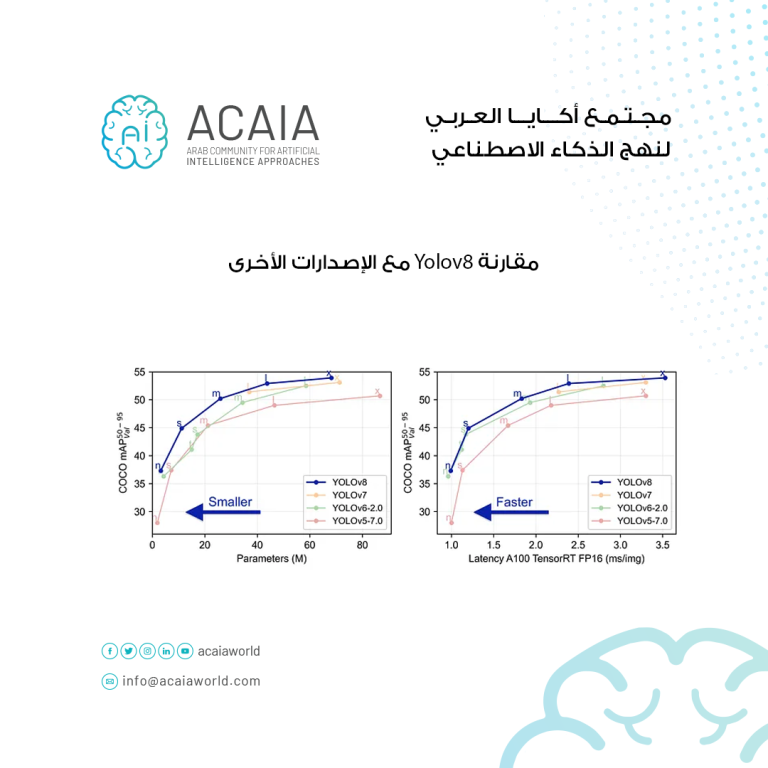
في YOLOv8، هناك خمسة نماذج مختلفة متاحة لكل فئة من فئات الكشف والتجزئة والتصنيف. YOLOv8 Nano هو أصغر وأسرع موديل ، في حين أن YOLOv8 Extra Large (YOLOv8x) هو الأبطأ والأكثر دقة من بينها.

تم تدريب نقاط فحص (checkpoints) اكتشاف الكائنات على مجموعة بيانات اكتشاف COCO بدقة صورة تبلغ 640. تم تدريب نقاط فحص تجزئة المثيل (Instance segmentation) على مجموعة بيانات تجزئة COCO بدقة صورة تبلغ 640.
نماذج تصنيف الصور التي تم اختبارها مسبقًا على مجموعة بيانات ImageNet بدقة صورة تبلغ 224.

4. التصدير (Export):
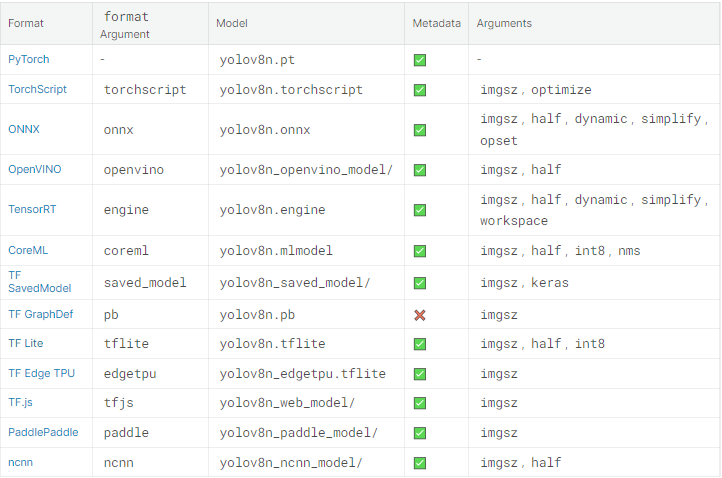
قم بتصدير نموذج YOLOv8 إلى أي تنسيق مدعوم أدناه باستخدام argument ال format، مثل: format = onnx.
 تصدير إلى ONNX أو OpenVINO لتسريع وحدة المعالجة المركزية حتى 3x.
تصدير إلى ONNX أو OpenVINO لتسريع وحدة المعالجة المركزية حتى 3x.
تصدير إلى TensorRT لتسريع GPU حتى 5 أضعاف.